Tokenization
Storing sensitive data on your company’s infrastructure often comes with a heavy compliance burden. For instance, storing payments data yourself greatly increases the amount of work needed to become PCI compliant. It also increases your security risk in general. To get around this, companies often tokenize their sensitive data.
Tokenization is a common scheme where sensitive data is swapped for tokens. Tokens are pseudorandom and don’t have exploitable value. These tokens are then stored in the company’s operational database while the original data is stored in a secure, isolated data store (often with a third party service). When the original data is required, it’s corresponding token can be exchanged for the original data. Because your company’s infrastructure is completely (or mostly) insulated from sensitive data, your compliance burden is greatly reduced.
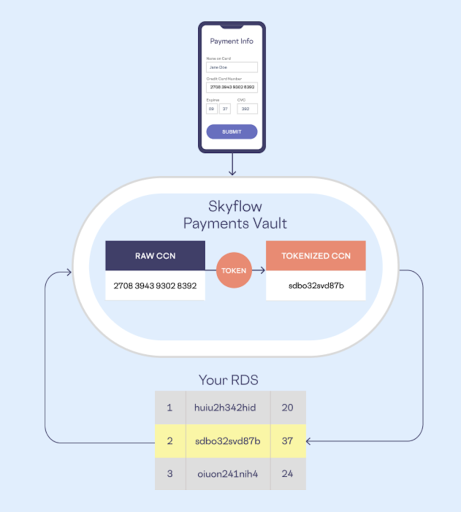
With Skyflow, you can implement an end-to-end tokenization scheme for your own product, drastically reducing your security and compliance burden in the process. Skyflow’s solution consists of three parts:
- Skyflow vaults can serve as the trusted third party service that stores your sensitive data and gives you tokens in return.
- Skyflow provides SDKs that can help you securely collect sensitive data client-side, which insulates your frontend code from handling sensitive data.
- Skyflow Connections help you use tokenized data in downstream APIs (for example Stripe, Alloy, etc.)
Skyflow token formats
Before you tokenize your data in Skyflow, you need to determine how you want the tokens formatted:
-
Do you want to preserve the format? The benefit of format preservation is that you can replace the sensitive values in your database without changing the schema or any validation rules. The token appears in the same format as the plain text data.
Example tokens for an email address
-
Do you want deterministic or non-deterministic tokens? Deterministic tokens enable matching and JOINing through tokens, which can greatly simplify your architecture and minimize the number of calls to the Vault required to perform analytical queries on the primary database. Deterministic tokens provide the same token for raw values that are inserted multiple times.
But because deterministic tokens are associated with a particular value the token changes whenever the value changes. This means that keeping your tokenized data store and the Skyflow data vault in sync requires you to tokenize values whenever they change and update the tokens in your data store.
Non-determinsitic - or ‘cell tokens’ - do not change when the underlying value changes so no ongoing sync is required. After the initial load of data into the Vault your tokenized data store contains a durable reference to the Vault which never changes as the value changes.
Example tokens for an email address (using format preservation)
-
Do you want to store data temporarily? Transient fields enable temporary storage of data and return non-deterministic tokens. You define the time to live (TTL) of the data when you create the field. Once the TTL expires, the data is automatically purged from your vault.
-
Do you want to make fields across multiple tables return consistent token values? Column groups make sure that fields across tables use the same tokenization settings and return consistent tokens. As long as they’re in the same column group, a value in
emailcolumns across multiple tables return the same token value according to the column group’s tokenization settings.
Next steps
Tokenize your data using Skyflow APIs.